


GPT5 was just announced in OpenAI youtube live stream. Sam Altman said that GPT-5 will come to ChatGPT (even to a free tier but not clear when), and to API starting today (August 7th, 2025). You can try GPT-5 here for free (with limits) and GPT-5-mini (with less strict limits).
Slides from the presentation with benchmarks:
This slide shows how GPT-5’s built-in chain-of-thought (“thinking”) dramatically boosts performance on two coding benchmarks versus its no-thinking mode and prior models:
1. SWE-bench Verified (software engineering)
GPT-5 without thinking: 52.8% GPT-5 with thinking: 74.9% OpenAI o3: 69.1% GPT-4o: 30.8%
Adding chain-of-thought yields a +22.1 pp gain over GPT-5’s own baseline, and surpasses OpenAI o3 by ~5.8 pp.
2. Aider Polyglot (multi-language code editing)
GPT-5 without thinking: 26.7% GPT-5 with thinking: 88.0% OpenAI o3: 79.6% GPT-4o: 25.8%
Here, chain-of-thought gives a +61.3 pp lift, pushing GPT-5 well ahead of o3 by ~8.4 pp and vastly outperforming GPT-4o.
Bottom line: Enabling GPT-5’s “thinking” unlocks huge accuracy improvements especially on challenging, academic‐style code tasks outstripping both its own no-thinking mode and earlier models.
The slide “WE-bench Verified” and “Aider Polyglot” demonstrates that GPT-5 substantially improves real-world coding accuracy over OpenAI o3 and earlier models:
SWE-bench Verified (Real-world software engineering tasks)
Metric: Accuracy (%) vs. Average output tokens
GPT-5:
Minimal context (~2 K tokens): 59 %
Low context (~4 K tokens): 69 %
Medium context (~8 K tokens): 72.5 %
High context (~11 K tokens): 75 %
OpenAI o3:
Low context (~5 K tokens): 64 %
Medium context (~8 K tokens): 67 %
High context (~14 K tokens): 69 %
Key takeaway: At every context-length tier, GPT-5 is roughly 5″“7 points more accurate””reaching higher accuracy with fewer tokens.
Aider Polyglot (Multi-language code editing)
Accuracy (%)
GPT-5:88 %
OpenAI o3:81 %
GPT-4.1:52 %
Key takeaway: GPT-5 delivers a significant boost in multilingual code-editing accuracy (7 points over o3, 36 points over 4.1).
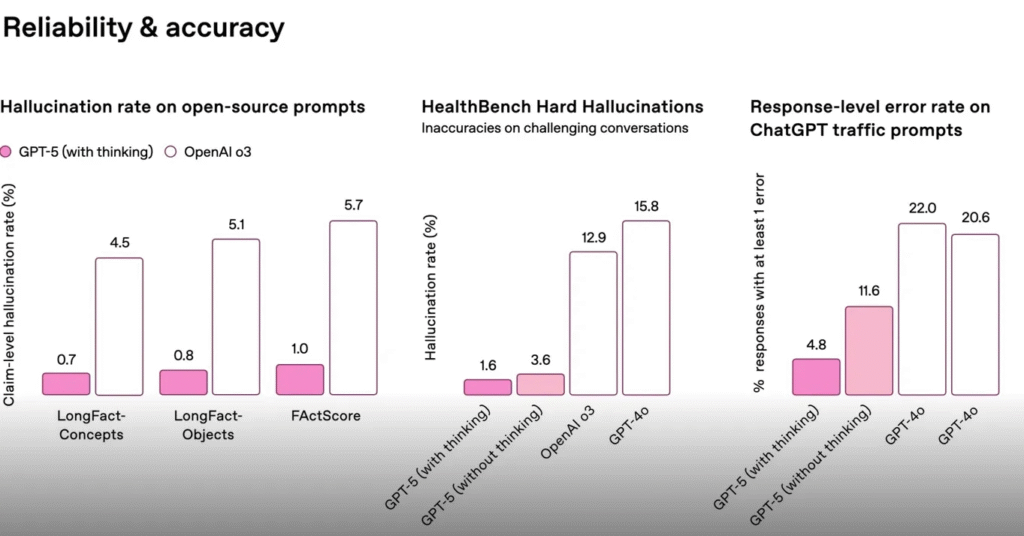
The slide “Reliability & accuracy” shows three ways in which GPT-5 (especially when using its built-in “thinking” or chain-of-thought mechanism) slashes hallucinations and errors compared to prior models:
Hallucination rate on open-source prompts Benchmarks: LongFact-Concepts, LongFact-Objects, FActScore GPT-5 (with thinking): 0.7 % |0.8 % |1.0 % OpenAI o3: 4.5 % |5.1 % |5.7 %
HealthBench Hard Hallucinations (Inaccuracies on challenging medical conversations) GPT-5 (with thinking):1.6 % GPT-5 (without thinking):3.6 % OpenAI o3:12.9 % GPT-4o:15.8 %
Response-level error rate on ChatGPT traffic prompts (% of responses with at least one error) GPT-5 (with thinking):4.8 % GPT-5 (without thinking):11.6 % GPT-4o: 22.0 % GPT-4: 20.6 %
Bottom line: Enabling GPT-5’s chain-of-thought (“thinking”) reduces hallucinations and errors by roughly 4–10× versus GPT-3/4.
GPT-5 retains near ceiling performance even at 256 K tokens (only ~10 pp drop from 8 K).
All other families (GPT-5 mini/nano, o3/o4-mini, GPT-4.1 variants) degrade much more rapidly as context length grows.
This underscores GPT-5’s unprecedented long-context understanding and robustness.
Summary of the OpenAI’s GPT-5 presentation: Sam Altman’s mentioned an availability to free tier users and claims that GPT-5 is not merely a faster language model but as a “a legitimate PhD level expert in anything any area you need on demand they can help you with whatever your goals are” and able to think just long enough to deliver the right answer, write entire software systems on demand, and guide complex personal or professional decisions.
1. A Leap in Core Intelligence
GPT-5 is trained to balance speed with deliberation, what the company calls its “reasoning paradigm.” Users no longer have to choose between a rapid response and a slow, more thoughtful reply; the model automatically “pauses to think” when a task needs deeper analysis. Altman framed the lineage this way: GPT-3 felt like chatting with a bright high-schooler, GPT-4o resembled a college student, and GPT-5 now converses like a seasoned, cross-disciplinary expert. Beneath that rhetoric are concrete gains on widely-watched academic benchmarks: 74.9 % on SWE-Bench Verified (software-engineering tasks), 88 % on Aider Polyglot (multi-language coding), new highs on MMMU (multimodal reasoning) and AIME 2025 (mathematical proofs).
2. Reliability and Safety
Perhaps more consequential than raw scores is GPT-5’s claimed reduction in hallucinations and deceptive behavior two longstanding weaknesses of large language models. OpenAI retrained its refusal system into a “safe-completion” regime: instead of a blunt “I’m sorry …,” the model partially answers, flags sensitive aspects, and points users to authoritative resources. Early internal evaluations suggest a noticeable drop in factually incorrect or misleading answers, especially on open-ended health and scientific queries.
3. A New Everyday Experience in ChatGPT
For end-users, GPT-5 arrives with a reimagined ChatGPT interface:
- Universal Access: The base GPT-5 model is now the default for free accounts (within usage limits), while Plus and Pro subscribers receive higher caps, and Enterprise/Education tenants get generous rate limits by default.(TechRadar)
- “Thinking” Toggle & Pro Mode: Paid users can explicitly summon an extended-thinking variant for tough problems.
- Memory & Personalization: ChatGPT can remember user preferences and, with permission, connect to Gmail and Google Calendar to propose schedules or draft emails in context.
- Voice & Visual Updates: A far more natural voice assistant now translates, tutors or brainstorms in real time; users can also skin the chat in custom colors and choose personalities ranging from concise to mildly sarcastic.(TechRadar)
4. Developer and Enterprise Tooling
On the platform side, OpenAI released three model sizes GPT-5, GPT-5 Mini, and GPT-5 Nano plus a long-context version that accepts up to 400 K tokens. New API features include:
- Custom Tools & Free-Form Outputs: Developers can constrain the model with regex or grammars instead of JSON-only schemas.
- Tool-Call Preambles & Verbosity Knob: The model can explain why it’s invoking a function and how verbose its answer should be (low, medium, high).
- Pricing: GPT-5 input tokens cost $1.25 per million; Nano is roughly 25× cheaper for latency-sensitive work.
Early enterprise pilots underscore the breadth of use cases. Amgen is using GPT-5 to parse clinical literature for drug discovery, BBVA to accelerate multi-week financial analyses into hours, and Oscar Health to interpret policy and patient records with higher accuracy than prior models. Meanwhile, the U.S. federal government has cleared the model for two million civil-service employees, hinting at public-sector adoption.
5. Demonstrations of Capability
The launch event featured live “vibe-coding” sessions where GPT-5 scaffolded a Next.js dashboard, built a 3-D castle game with interactive characters, and generated a dynamic SVG simulation of the Bernoulli effect all from conversational prompts. For non-technical audiences, the most resonant vignette came from Carolina Millon, a patient diagnosed with multiple cancers who leaned on GPT-5 to decode biopsy reports, weigh radiation options and craft physician questions, illustrating the system’s emerging role as an informed companion in high-stakes decisions.
6. Broader Implications
GPT-5’s blend of reasoning depth, agentic autonomy and multimodal input ports OpenAI’s next chapter: software that not only answers but acts planning parties, booking supplies, refactoring legacy code or serving as a bespoke tutor. The company frames this as “software on demand,” foreshadowing a near future where specialized apps yield to AI agents that materialize when summoned. The safety work and pricing strategy suggest an intent to scale responsibly yet pervasively, embedding GPT-5 in productivity suites, IDEs, voice assistants and government workflows alike.
Conclusion
In releasing GPT-5 to both the free public tier and high-throughput enterprise channels on day one, OpenAI signals confidence that its fifth-generation model is no longer an experiment but foundational infrastructure an expert co-worker, polyglot tutor and creative studio rolled into a single, ever-improving system. Whether measured by benchmark curves, real-time demos or early industry testimonials, GPT-5 stakes a credible claim as the most capable, reliable and versatile general-purpose AI yet deployed, narrowing the gap between today’s assistants and tomorrow’s AGI.


Well written. For PDF splitting and merging, I recommend https://pdfpanel.com.
Pretty! This has been a really wonderful post. Many thanks for providing these details.
Good communication support
Good communication support
Bitcoin Invest offers secure ROI plans designed for all types of investors worldwide.
Great information shared.. really enjoyed reading this post thank you author for sharing this post .. appreciated
I just like the helpful information you provide in your articles
I really like reading through a post that can make men and women think. Also, thank you for allowing me to comment!
Enjoy cool wonderful like superb perfect choice brilliant.
Your blog has quickly become one of my favorites. Your writing is both insightful and thought-provoking, and I always come away from your posts feeling inspired. Keep up the phenomenal work!
you are in reality a good webmaster The website loading velocity is amazing It sort of feels that youre doing any distinctive trick Also The contents are masterwork you have done a fantastic job in this topic
This post answered a question I’ve had for ages. Thank you!
This post is jam-packed with valuable information and I appreciate how well-organized and easy to follow it is Great job!
Tarafbet’te canlı maç izlemek keyifli.
Bahis seçenekleri oldukça harika, her lig mevcut.
Your blog is a treasure trove of knowledge! I’m constantly amazed by the depth of your insights and the clarity of your writing. Keep up the phenomenal work!
I tried your suggestion and it worked perfectly for me. Cheers!
There is definately a lot to find out about this subject. I like all the points you made
Appreciate the time you put into this — it’s packed with value.
Buddy is an amazing new social media platform.
Nice article! I especially liked the actionable checklist.
Such a clear explanation — I feel more confident tackling this now.